
FlashAttention是目前LLM推理最常用的Attetion算子实现框架,广泛使用在了vLLM, TensorRT-LLM中,本文是笔者关于FlashAttention的学习笔记,水平有限,如果有理解错误的地方也请指出。
参考材料
FlashAttention-V1论文: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
From Online Softmax to FlashAttention
从Online-Softmax到FlashAttention V1/V2/V3
FlashAttention:加速计算,节省显存, IO感知的精确注意力
背景及动机
从论文题目可以看出,FlashAttentionV1工作通过IO-Awareness技术:
Fast: 加速了Attention的计算过程Memory-Efficient: 优化了Attention计算过程中的显存使用Exact Attention: 精确Attention计算结果,和标准Attention计算结果相同
FlashAttentionV2工作主要是在V1上优化了并行和Work划分。
标准Attention的计算公式如下:
上面的计算可以分为三个部分:
- $S=QK^T \in R^{N \times N}$
- $P=softmax(S) \in R^{N \times N}$
- $O=PV \in R^{N \times d}$
计算过程图示及算法伪代码如下:
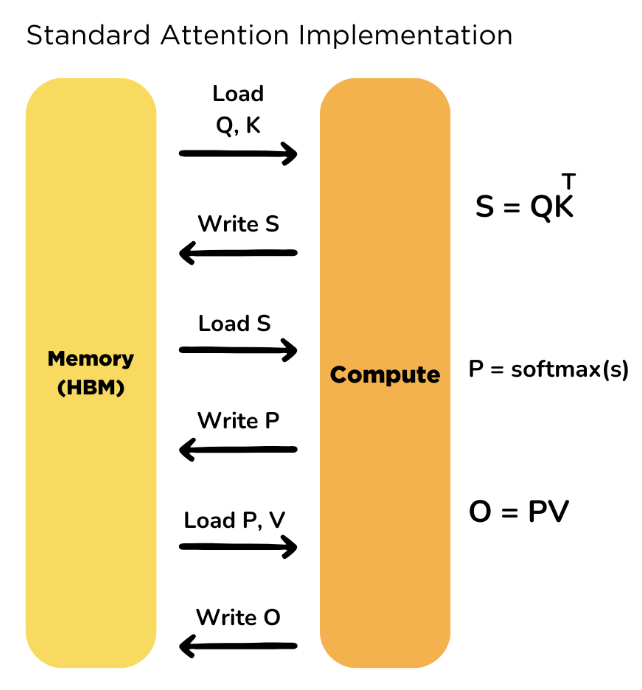
上面的计算过程有两个缺点:
- 显存占用多,中间计算结果矩阵$S,P \in R^{N \times N}$导致了$O(N^2)$的显存占用,通常来说,$N >> d$
- 大量的HBM的读写操作,HBM的带宽很低,会导致整个计算过程变慢
GPU内存分层: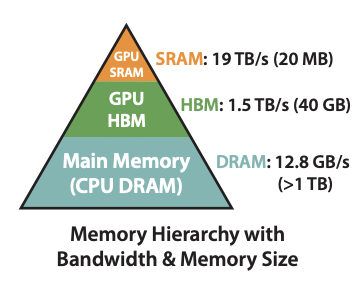
FlashAttention V1 V2优化
对比标准Attention的实现,flash attention 的核心思路是通过分块计算,将中间计算 fuse 在一起,避免来回读写中间,减少访问 HBM 的次数,提高计算效率。具体如下:
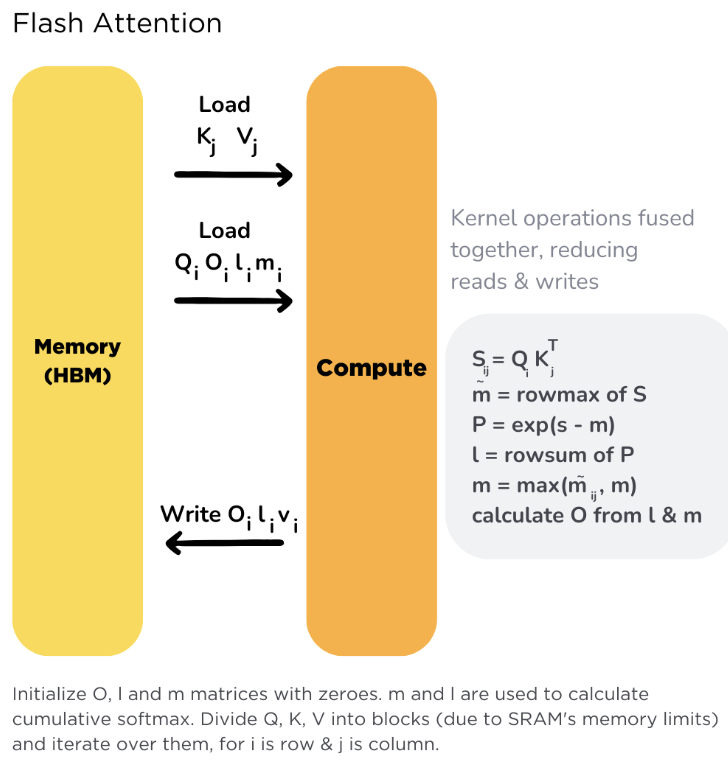
1. Tiling: 矩阵乘法,具有分块和累加的特性,一个大的矩阵乘法,可以通过Tiling技术,分成小块加载到高速的SRAM完成计算,然后通过将各个分块矩阵乘的结果进行累加获得最后的正确结果,减少HBM的总访存量。tiling技术在矩阵乘法GEMM算子实现中都会用到。
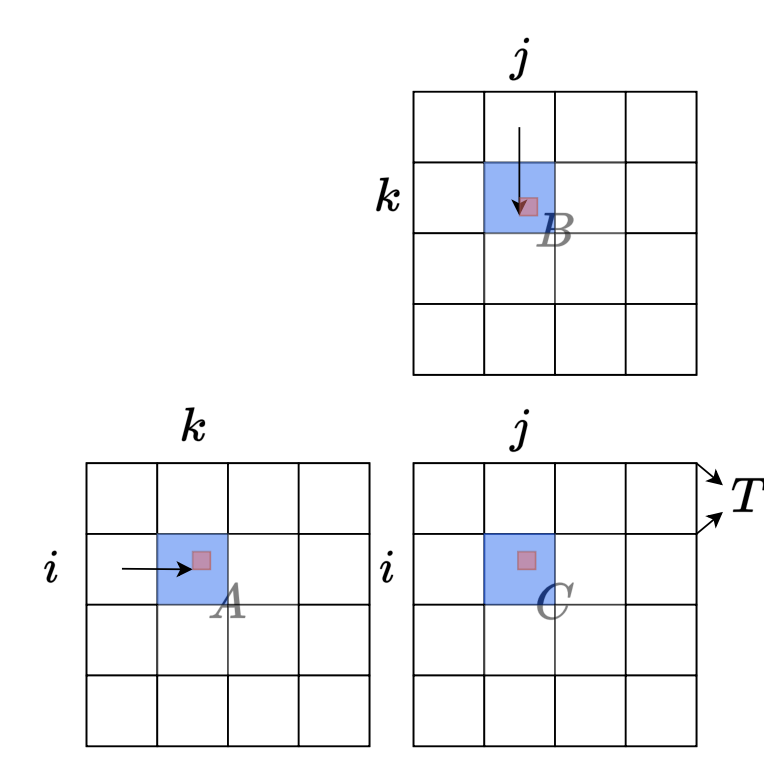
想了解GEMM优化的同学可以看下面的材料,感觉都写的挺好的:
深入浅出GPU优化系列:GEMM优化(一)
- online-softmax: 遗憾的是,Attention计算过程除了矩阵乘法以外,主要问题是有个Softmax的分母项依赖于全局的一行输入,也就是说$P_i=softmax(Q_iK^T)$依赖$Q_i$矩阵块与整个$K^T$矩阵完成计算。FlashAttention和online softmax想解决的核心问题,正是如何将算法本身从这个全局的依赖中解耦,从而可以使用Tiling进行快速的片上计算
Online Softmax个人理解:
我们想计算一个$X \in R^{BT}$上的$softmax$分布, 表达式如下:
其中,m=max(X), 减去m是为了防止指数运算溢出(safe softmax实现)。
假如我们开了天眼,已经知道全局的$m=max(X)$,和$l=\sum_{i=1}^{B*T}{e^{x^i-m}}$,那么softmax过程可以拆分为:
其中,$X$被分为$T$个小块,$X_{T_i} \in R^{B}$。这样看着可以完成tiling计算的需求。
但是我们目前没有天眼的,只能知道所有已计算过的分块中$m$,以及$l$, 即:
- 分块1:
$softmax(X_{T_1})=\frac {exp(X_{T_1}-m_1)}{l_1}$
$m_1 = max(X_{T_1})$
$l_1=sum(exp(X_{T_1}-m_1))$ - 分块2:
$softmax(X_{T_2})=\frac {exp(X_{T_2}-m_2)}{l_2}$
$m_2 = max(m_1, rowmax(X_{T_2}))$
$l_2=sum(exp(X_{T_1,T_2}-m_2))={l_1}e^{m_1 - m_2}+sum(exp(X_{T_2}-m_2)$
$softmax(X_{T_1,T_2})=\frac{l_1}{l_2} softmax(X_{T_1}) e^{m_1 - m_2}+softmax(X_{T_2})$ - ….
- 分块T:
$softmax(X_{T_T})=\frac {exp(X_{T_T}-m)}{l}$
$m = m_T = max(m_{T-1}, rowmax(X_{T_T}))$ 得到了前面开天眼的l和m
$l = l_T =sum(exp(X-m))={l_{T-1}}e^{m_{T-1} - m}+sum(exp(X_{T_{T}}-m)$
$softmax(X)=\frac{l_{T-1}}{l} softmax(X_{T_1,….T_T-1}) e^{m_{T-1} - m}+softmax(X_{T_T})$
这样分块迭代是可以满足tiling要求,并计算出精确的softmax的,可以对着下面算法伪代码看,流程是一样的:
唯一区别是,softmax中间存放的结果是$exp(X_{T_1}-m_1)$这种格式,把每次除l的放缩部分拿最后算了,这样可以进一步加速。
Triton源码学习
代码来源:Fused Attention
FlashAttention仓库内容太多了,Triton实现比较精简,更容易阅读
1 |
|